Le niveau de preuve des publications : divers degrés.

Dans les articles sur la p-valeur et sur l’inversion de l’hypothèse nulle, nous avons évoqué la notion de niveau de preuve ou de qualité de la preuve. En effet, toutes les études ne se valent pas.
Mise à jour le 26/03/2021
Il existe une gradation du niveau de preuve généralement représentée sous forme de pyramide ou d’une échelle verticale. Les images 1 et 2 montrent de telles représentations graphiques.
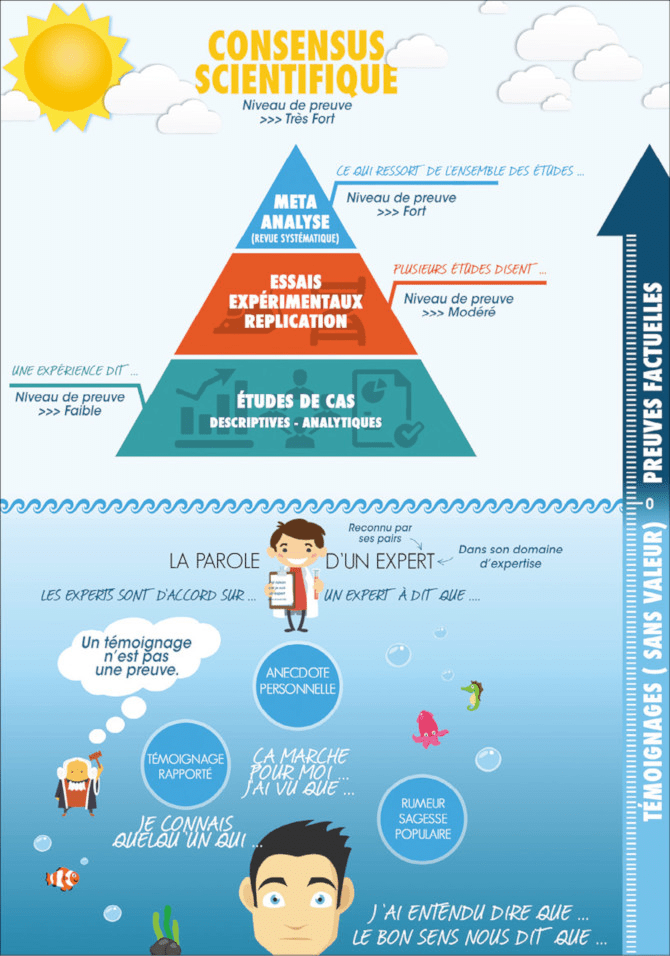
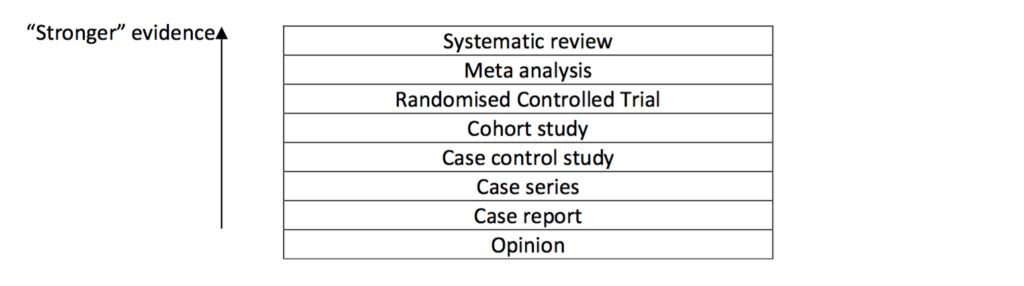
L’échelle du Royal College of Veterinary Surgeons (image 2) représente assez bien les différents types de « preuves » (evidence en anglais) qu’on peut rencontrer en médecine vétérinaire.
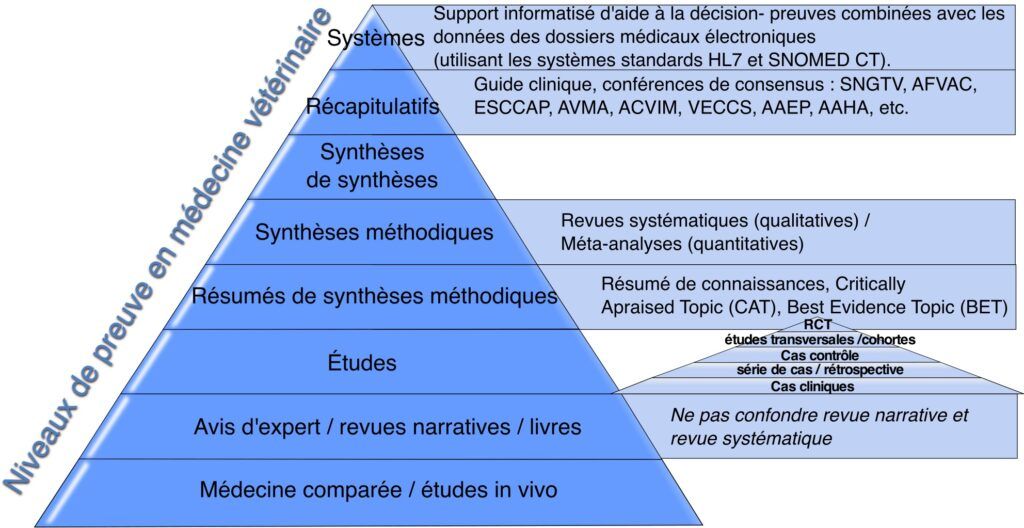
Fricke replace la pyramides des études dans le cadre plus large des ressources de connaissances vétérinaires.
Les études à fort niveau de preuve.
Les essais cliniques
Les études les plus robustes sont les études dites randomisées, contrôlées et en double aveugle (RCDA).
- Contrôlées : le protocole de l’étude prévoit au moins un groupe contrôle qu’il soit positif ou négatif. Par exemple, lors d’un essai sur un médicament, un groupe contrôle négatif sera un groupe recevant un placebo. Les animaux d’un groupe contrôle positif recevront, eux, un médicament connu utilisé dans l’indication testée. Les tests statistiques dépendront de la nature de ces groupes contrôles. Dans un cas, les tests montrent l’efficacité propre d’un traitement « dans l’absolu » car comparé à un placebo. Dans le cas d’un groupe contrôle positif, les tests effectués sont souvent des tests de non infériorité car montrer une efficacité supérieure d’un médicament A par rapport à un médicament B demande une puissance statistique très importante.
- En double aveugle : le protocole de l’étude prévoit que les propriétaires des animaux inclus dans l’étude ne savent pas à quel groupe ils appartiennent et les expérimentateurs ne le savent pas non plus. Ainsi ni les sujets ni les expérimentateurs ne risquent d’être influencés par les différents biais cognitifs inévitables dans le cas contraire.
- Randomisées : l’appartenance à un groupe de chaque sujet est déterminée par le hasard. Cela garantit que les différents groupes représentent des populations « identiques » en tout point sauf sur l’objet de l’étude.
Il est important que la taille de chaque groupe soit calculée avant l’expérimentation en fonction de la puissance statistique souhaitée. Pour augmenter la puissance statistique de l’étude, il suffit généralement d’augmenter la taille de l’échantillon. Dans ce cas, en plus du problème de coût lié à l’augmentation de la taille de la population, se pose un problème plus délicat : le test peut mettre en évidence une différence statistiquement significative mais correspondant à une réalité biologique intangible. Nous verrons dans un autre article comment par inférence, il est possible de déterminer l’intérêt ou non des résultats bruts. Enfin il faut être prudent lorsque le nombre de sujets n’est pas fixé au début de l’étude car il est possible de fausser le résultat en décidant d’arrêter l’expérimentation lorsque le résultat des calculs est conforme à ceux souhaités.
Ce n’est que si toutes ces conditions sont remplies qu’on peut affirmer que les corrélations observées sont des liens de cause à effet.
Limites
- Prix : ces études coûtent très cher. C’est pourquoi beaucoup d’entre elles sont financées par des laboratoires pharmaceutiques. La qualité de ces études n’est pas à remettre en cause à priori mais se pose le problème des biais de publication, qui consiste à ne publier que les études dont les résultats arrangent les auteurs ou les commanditaires. Par conséquent, ces études financées par les laboratoires doivent être considérées comme des preuves dégradées à priori. C’est aussi la raison pour laquelle il y en a peu en médecine vétérinaire. Par exemple en 2010, Alrt et al ont répertorié 287 publications traitant de la reproduction canine et seulement 8 étaient des études randomisées en double aveugle ! (1) Le marché vétérinaire est un petit marché en terme de volume financier. Par conséquent, il attire peu les investissements mis à part dans certains domaines généralement motivés par la société (Santé publique, bien être animal, etc).
- Méthodologie très stricte : par exemple, si lors d’un essai, pour rendre aveugle, on donne des flacons étiquetés A et des flacons étiquetés B à l’expérimentateur en lui donnant une séquence d’attribution aléatoire, les conditions de double aveugle ne sont pas respectées car même si l’expérimentateur ne sait pas à quoi correspondent A et B, il va nécessairement connaître les deux groupes. (Ici la bonne méthode serait de distribuer les flacons étiquetés 1,2,3,…n : ainsi la séquence est définie à l’avance et l’expérimentateur ne peut pas savoir si un flacon correspond à un groupe ou à un autre.)
- Bonne compréhension des statistiques.
Les enquêtes épidémiologiques prospectives.
Principe
Dans certaines situations, il n’est pas possible de réaliser des expériences contrôlées pour différentes raisons : éthiques, pratiques, etc. Dans ce cas, lorsqu’on souhaite un niveau de preuve suffisant, il est préconisé de réaliser des études de cohortes. Les enquêtes épidémiologiques prospectives sur de grandes cohortes possèdent un bon niveau de preuve.
Une cohorte, c’est une unité épidémiologique. C’est un ensemble de sujets, d’animaux dans le cas qui nous concerne, qui forment une population homogène sur certains critères définis. Ces animaux seront suivis dans le temps. Prenons l’exemple de chercheurs voulant étudier l’impact des blessures et des maladies sur l’entraînement des jeunes purs-sangs. Pour cela, ils vont suivre un groupe de jeunes purs-sangs de 2 et 3 ans à l’entraînement : les animaux recrutés forment une cohorte et tous les événements de santé seront notés ainsi que leurs impacts sur le programme d’entraînement pendant un an. (3) La cohorte est donc une unité statistique voire épidémiologique.
Dans ces études, il faut distinguer deux cas de figure :
- Les cohortes de malades : une population atteinte d’une maladie est recrutée pour un suivi longitudinal afin d’étudier l’évolution de la maladie ou les effets dans le temps d’un protocole thérapeutique. On est ici dans une approche purement biomédicale, toutefois il peut y avoir un apport complémentaire des sciences sociales. Ces cohortes représentent quelques centaines à quelques milliers de patients qui seront suivis de très près pendant une durée donnée ou indéterminée selon le design de l’étude.
- Les cohortes de population : l’objet de ces enquêtes, c’est d’étudier les causes de maladies souvent multifactorielles. Les populations recrutées sont importantes. Au départ sont recrutés des sujets indemnes de la ou des maladies étudiées. Ces enquêtes coûtant très cher et impliquant beaucoup de sujets, une même cohorte est souvent utilisée pour plusieurs maladies. Les sujets inclus subissent de manière prospective un questionnaire portant sur de nombreux aspects de leur vie sociale, environnementale, leurs us et coutumes, et un certain nombre de tests médicaux et biologiques. Ils sont suivis ensuite sur la durée et tous les événements médicaux comme les éventuelles modifications dans la vie des sujets, sont notés .
Limites
La première limite est que lorsque la maladie étudiée est rare ou que l’influence du facteur de risque est faible, alors pour mettre en évidence des « effets » avec une précision suffisante, il faut des cohortes de taille énorme, jusqu’à plusieurs millions de sujets, ce qui n’est pas possible. Ces études ne sont donc pas faites pour étudier les effets trop faibles.
Ces études contiennent aussi très souvent certains biais très difficiles à éviter :
- Biais de sélection
- Biais d’attrition
- Données répétées et données manquantes
De plus se pose la difficulté de détection des pathologies incidentes et de la caractérisation du phénomène à étudier : quels seront les symptômes pris en considération à la fois pour caractériser la maladie ou pour l’exclure ainsi que ceux qui serviront de marqueur d’évolution. En clair, quels critères d’inclusion et d’exclusion sont pertinents et selon quelles combinaisons ? Prenons l’exemple d’un suivi longitudinal post vaccination contre Mannheimia haemolytica chez des veaux. Que va-t-on considérer comme échec de vaccination : des animaux qui ont une hyperthermie persistante de plus de 48h ? Une toux ? Un jetage ? Muqueux ou muco-purulent ? Un prélèvement par Aspiration Trans-Trachéale ou par écouvillonnage nasal ? Avec isolement des pathogènes ou juste recherche de M. haemolytica ? Du choix des critères retenus dépendra une partie des résultats.
On ne peut, de plus, se reposer sur les déclarations des sujets car ils peuvent, par exemple, ne pas détecter la pathologie, ou en détectant la maladie s’exclure eux-même des études. On doit recourir au diagnostic mais celui-ci étant imparfait, on passe à côté de la maladie dans certains cas.
Corrélation n’est pas causalité ?
Cette affirmation est très généralement vraie. Ainsi les études observationnelles ne permettent pas la plupart du temps d’aller plus loin qu’une observation de la corrélation entre un élément considéré comme facteur de risque et un phénomène pathologique. Toutefois lors d’études observationnelles bien menées, il est possible de considérer que la corrélation montre un lien de causalité. Nous verrons dans un prochain article quels sont les critères utilisés pour cela.
Les études à niveau de preuve moyen.
Les essais cas-témoin (case control study), lorsque la méthodologie est respectée, apportent des preuves intéressantes bien que moins robustes que les essais randomisés et les études épidémiologiques de cohorte. Ces études comparent des animaux ayant, par exemple, une maladie (les cas) et des animaux indemnes (les témoins). Ces derniers sont en proportion de 1 à 4 par rapport aux cas, en fonction des outils statistiques qu’il est prévu d’utiliser. On recherche ensuite dans l’histoire des animaux, les éléments qui peuvent avoir eu un impact sur la maladie (recherche de facteurs de risque généralement). Ce sont donc des études rétrospectives.
Ces essais sont utiles pour explorer des maladies plutôt rares, ou pour réaliser des études exploratoires. Elles présentent aussi l’avantage d’être moins onéreuses que les études de fort niveau de preuve.
Les études à niveau de preuve médiocre.
Études à protocole dégradé
Dès qu’on retire un élément du protocole d’essai clinique – la randomisation, le double aveugle, le groupe contrôle – on dégrade sa qualité. Il n’est parfois pas possible d’avoir un protocole totalement rigoureux. Ces études dégradées ont donc forcément un niveau de preuve plus faible que les études RCDA. Comme il est difficile voire impossible de quantifier les biais introduits, ces études sont d’un niveau de preuve très médiocre.
Études rétrospectives
De même, contrairement aux études de cohortes prospectives, les études rétrospectives ont une valeur de preuve faible. Ces études sont utiles lors d’études exploratoires ou éventuellement pour valider un modèle montré par prospective.
Les séries de cas et « case report »
La description de cas cliniques isolés ou d’un ensemble de cas présente un très faible niveau de preuve. En effet, il n’y a aucun point de comparaison par des groupes contrôles. Ces études concernent un faible nombre de cas, il est donc très hasardeux de vouloir tirer des conclusions solides à partir de tels éléments. Ces preuves sont toutefois intéressantes lors d’études préliminaires ou pour mettre en évidence des éléments discordants par rapport à l’état de l’art connu à un instant T. Par exemple elles permettent d’alerter les praticiens lors d’émergence d’une nouvelle maladie ou lors de détection d’effets secondaires rares.
Les publications à très haut niveau de preuve
Les méta-analyses
Il faut se souvenir, comme on l’a déjà dit, qu’une seule étude même bien réalisée ne signifie rien. Celle-ci doit être au minimum reproduite et, mieux, répliquée par une ou plusieurs équipes indépendantes. En effet, souvenez-vous de ce que nous disions dans l’article sur la p-valeur. Il est tout à fait possible même avec une étude bien menée de trouver un résultat statistiquement significatif qui est faux pour de simples raisons mathématiques. C’est donc la répétition de l’obtention d’un résultat donné qui va assurer sa validité (jusqu’à preuve du contraire).
Certaines études consistent à compiler les essais cliniques sur un sujet et d’en agréger les résultats : ce sont les méta-analyses. Celles-ci reposent sur une méthodologie rigoureuse. Elles permettent de dégager des conclusions plus robustes car agréger les résultats revient à augmenter la puissance des tests. Malheureusement elles ne sont pas toujours possibles du fait de la disparité des protocoles d’étude, ou le faible nombre de celles-ci.
Par exemple, il existe des méta-analyses sur le traitement des plaies qui repose sur des études rétrospectives donc à faible valeur individuellement mais la compilation sous forme de méta-analyse donne une valeur de preuve relativement forte.
Les revues systématiques
Parfois appelées synthèses méthodiques, les revues systématiques ne doivent pas être confondues avec les revues narratives. Elles répondent à une méthodologie précise illustrée dans l’image 3.
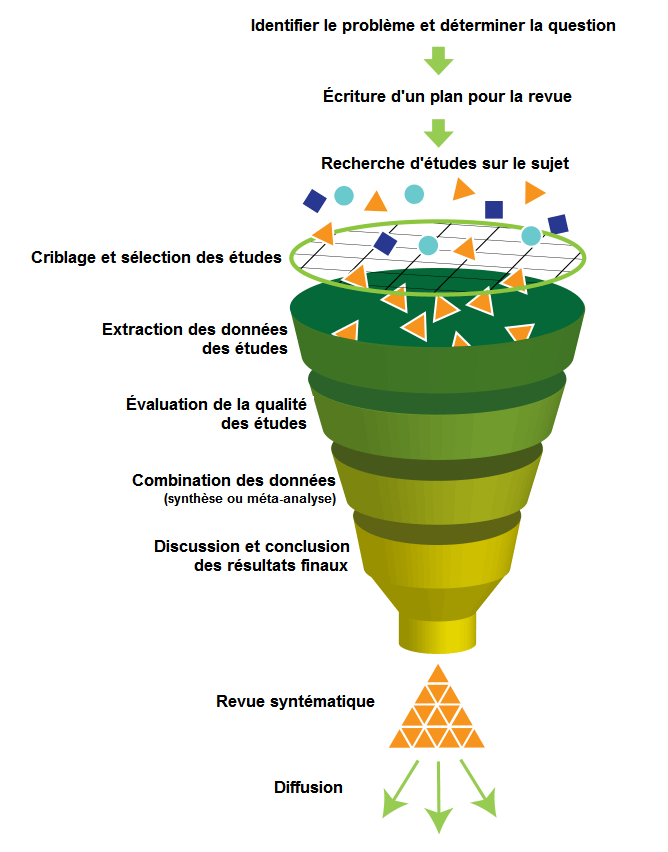
Elles prennent en considération toutes les études à niveau de preuve suffisant (fixé au départ dans le protocole de la revue). Les résultats ne sont pas agrégés mais les études sont comparées entre elles afin de dégager des conclusions les plus robustes possible.
Ces publications sont longues et ardues à lire. Il s’est donc développé une littérature spécifique de critique et résumé des revues systématiques : les Critically Appraised Topics (CATs). Celles-ci devraient être privilégiées par les praticiens vétérinaires en particulier en médecine bovine, d’après Buczinski et Vanderweerd (2).
Il ne faut pas confondre les revues systématiques qui prennent en compte toutes les publications données sur un sujet en fonction d’un certain nombre de critères définis, avec les revues narratives. Ces dernières sont des articles qui traitent d’un sujet en se référant à un certain nombre de publications, souvent en suivant l’expérience et l’expertise de l’auteur de la revue. Elles contiennent donc nécessairement plus de biais que les revues systématiques.
Le consensus médical
Peu nombreuses en médecine vétérinaire, les conférences de consensus et les « recommandations pour la pratique clinique », deux méthodologies très proches, ne correspondent pas vraiment à des niveaux de preuve. Toutefois les écrits qu’elles produisent sont les guides les plus robustes à un instant T pour la pratique médicale. La méthodologie est rigoureuse : un promoteur initie la conférence, il convoque un comité organisateur indépendant qui va préparer la conférence, celui-ci convoque des experts, un « public » et un jury. Le groupe d’experts va répondre de manière argumentée aux questions de la conférence. Le « public » est aussi convié à s’exprimer. Ensuite, le jury va délibérer à huis clos pour produire un texte court qui sera la synthèse de la conférence. Un texte long qui reprendra l’ensemble des éléments présentés par les experts et le public est aussi produit la plupart du temps.
Par souci de transparence, le promoteur sera cité tout au long de la procédure. Ainsi le laboratoire Pfizer et la Société Française de Buiatrie, promoteurs de la conférence de consensus « l’antibiothérapie chez les bovins » en mai 2002, sont cités sur l’ensemble des documents produits.
Les consensus et les RPC ne sont pas des guides opposables d’un point de vue juridique. Toutefois en médecine humaine, ils servent de base à la rédaction des références médicales opposables.
Quelques spécificités du monde vétérinaire
La littérature facilement accessible aux vétérinaires praticiens est surtout constituée par des revues qui recueillent des cas cliniques ou des articles de revue narratifs. Quelle que soit la qualité de ces revues, les praticiens n’ont donc en accès facile que des publications à faible valeur de preuve.
Les indices
Comme vu dans l’article « Preuve ou indice », les témoignages n’ont pas valeur de preuve. Cela inclut les avis d’expert et les articles d’opinion qu’on retrouve beaucoup dans la presse vétérinaire et aussi en complément des revues narratives et des cas cliniques dans les revues professionnelles. C’est ce qui est représenté dans l’image 1, dans la partie basse en dessous de la pyramide. Toutefois on peut tempérer cet avis concernant les synthèses narratives. À condition que la question clinique pose peu de problème (donc hors nouveauté, polémique, etc) et à condition que la synthèse soit publiée dans une revue de qualité alors ces écrits reflètent le plus souvent l’état de l’art et sont de plus de bonnes sources de bibliographie. On peut donc souvent se contenter de celles-ci dans de nombreuses situations. Elles restent malgré tout insuffisantes dans le cadre d’une recherche exhaustive de la preuve lorsque celle-ci s’avère nécessaire.
ONE MORE THING !
Plus le niveau de preuve est élevé plus la preuve est « vraie » ? Et bien non. Tout cet article s’est contenté de présenter les différents niveaux de preuve selon le « design » de l’étude. Mais une étude très bien menée peut parfaitement aboutir à une conclusion fausse : si la question initiale posée n’est pas la bonne, si la taille d’effet est faible et donc que le résultat statistiquement significatif ne correspond en fait à aucune réalité clinique…
Toutefois plus le niveau de preuve est élevé, plus on peut avoir confiance dans la qualité de cette preuve.
De plus il ne faut pas prendre l’échelle comme une valeur trop rigide. En effet selon la question posée certains types d’études répondront mieux à la question que d’autre. Par exemple pour déterminer l’efficacité de la vaccination vis à vis du VRSB des études randomisées en aveugles seront les plus efficaces. Par contre pour déterminer le pronostic d’une babésiose canine traitée à l’imidocarbe, des études prospectives de cohortes répondront mieux à la question. Bien sûr à condition qu’elles soient bien menées mais ça, ce sera l’objet d’un prochain billet.
- Arlt, S., Dicty, V., Heuwieser, W. 2010. Evidence-based medicine in canine reproduction: Quality of current available literature. Reproduction in Domestic Animals 45: 1052–1058.
- Buczinski et Vanderweerd, 2012, Médecine vétérinaire factuelle : une (r)évolution naturelle pour le vétérinaire praticien bovin, Bull. Acad. Vét. France, 165 (4), 325-329. [Site de l’académie]
- Bailey, CJ., Reid, SWJ., Hodgson, DR., Rose, RJ.(1999) Impact of injuries and disease on a cohort of two- and three-year-old thoroughbreds in trainingVeterinary Record 145, 487-493. [Europepmc] DOI: 10.1136/vr.145.17.487
- Fricke S. A Revised Evidence Pyramid for Veterinary Clinical Resources. In: Best Evidence. Better Care. The 7th Evidence-Based Veterinary Medicine Association (EBVMA) Symposium ; 2015:3.